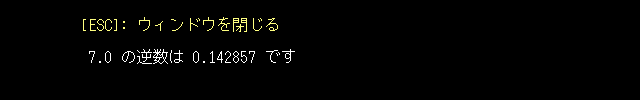
C で OpenGL グラフィックスを使いやすくするためのユーティリティとして GLUT がある。GLUT
が提供する関数を使うと簡単に図形が描画ができ,
しかも Windows でも Mac でも同じように使えるので, 筆者も利用している。
文字を描画するための glutBitmapCharacter()
という関数があるので, グラフィック画面上に簡単な説明を書いたり数値を表示したりすることもできる。
描けるのはビットマップフォントで, 等幅フォント, HELVETICA, TIMES_ROMAN などが用意してある。
この関数のままではちょっと使いにくいが, たとえば下の
render_string() のような関数にすれば使い勝手がよくなる。
render_string() … 文字列描画関数の例
ところで, GLUT の文字列描画関数で使える文字は ISO 8859-1
のラテン系文字だけで, 残念ながら日本語は使えない。では, 日本語を描画するにはどうしたらよいのだろう。
たとえば FTGL
というライブラリを入れると, 多言語の文字がいろいろなレンダリング方法で描画できるようになる。
しかし, システムにインストールされているフォントを使うので,
実行プログラムは同じ環境がないと動かないものになってしまう。
画面上に説明のための日本語を表示するだけなら16ドット程度のビットマップフォントで十分だし,
環境に依存しないようにするにはフォントを自前で用意したらいいのではないか。
というわけで, ビットマップフォントをデータとしてもつ日本語文字列描画関数を作ったので, 紹介したい。
GLUT が使える環境さえあれば, ほかに何も追加せずに使えるはずだ。
このヘッダファイルの中で, 日本語のビットマップフォントを描画する関数を定義している。
また, 16ドットのビットマップデータ (Base64 エンコードしたもの) を配列として与えている。
したがって, GLUT が使える環境なら, つぎのように jfont.h
をインクルードするだけで日本語文字列が描画できるようになる。
#include "jfont.h"
ここで, x と y には先頭文字左下の座標を, str には UTF-8 コードの日本語文字列を与える。 BUFSIZ は stdio.h で定義されている標準バッファサイズで, ふつう 512 バイトまたは 1024 バイト。 入力文字列はこれよりも短いものでなければならない。int render_jstring(int x, int y, char str[BUFSIZ]);
char s[256];
glColor3f(1.0, 1.0, 0.5);
render_jstring(80, 32, "[ESC]: ウィンドウを閉じる");
glColor3f(1.0, 1.0, 1.0);
sprintf(s, "%4.1f の逆数は%9.6f です", 7.0, 1.0/7.0);
render_jstring(80, 64, s);
入力文字のコードを Unicode (UTF-8) にしたのは, Shift_JIS
コードだと一部の文字が文字化けするので, それを避けるためだ。
なお, 16ドットビットマップフォントの漢字部分には Yu=Izumi
氏の「出水ゴシック16ドット β6版」 (http://izumilib.web.fc2.com/)
を使わせていただいた。
また, 半角文字と全角文字の非漢字部分 (JIS 2121~2D7C), および拡張文字 (JIS 7921~7C7E)
のうち出水ゴシックフォントに含まれていない 84 文字は自分でデザインした。
* jfont.h には, render_jstring()
関数, 数千文字のビットマップデータのほか, 日本語文字コード変換のための関数
utf82sjis(), コード変換テーブルのデータも含まれている。
データを配列として持っているため, コンパイル後の実行プログラムのサイズがやや大きくなることを了解されたい。
jfont.h (670 KB) … 日本語文字列描画関数 render_jstring() とビットマップフォントを含むヘッダファイル (2021/11版)
参考: fjhn16x.bdf, fjzn16x.bdf … jfont.h に含まれているビットマップフォントの BDF 形式元データ (半角および全角)
参考: bdf2b64all.c … BDF フォントのビットマップデータを Base64 エンコードするプログラムのソース (2021/11版)
#include "usjconv.h" |
usjconv.h は jfont.h に含まれている UTF-8 → Shift_JIS
の文字コード変換関数 utf82sjis() とその関連部分を独立させたもの。
上のように include すると使えるようになる。
日本語の文字コードを変換するだけで描画はしないので, GLUT のない環境でも使える。
ソースコードの日本語文字列は UTF-8 で書いているが, Windows のコマンドプロンプト画面には
Shift_JIS で出力したいというときに使うとよい。
この関数は jfont.h にも含まれているので, jfont.h をすでに
include しているときは usjconv.h の include は不要。
なぜ文字コード変換が必要か, すこし説明しておこう。
Windows の端末画面 (コマンドプロンプト) の文字コードは Shift_JIS に設定されている。
ところが, 端末画面に日本語を出力するため " " で囲った文字列定数を
Shift_JIS で与えると, 2バイト目が 5C のとき, これが エスケープ文字
\ と解釈されてしまうので文字化けするのだ。
そこで, 文字列定数を UTF-8 で書き, その文字コードを Shift_JIS
に変換してから端末画面に出力するようにすると, 文字化けを防ぐことができるというわけだ。
ちなみに, Mac OS X の端末画面
(ターミナル) の標準文字コードは UTF-8 なので, ソースプログラムの文字列を UTF-8 で書いて, そのまま画面に出力すればよい。
Windows のような文字コードの変換は Mac では不要だ。
文字コード変換プログラムの使い方はつぎの通り。
int ut82sjis(char src[BUFSIZ], char dst[BUFSIZ]);
ここで, src は入力文字列 (UTF-8), dst は出力文字列 (Shift_JIS) だ。以下に使用例を示す。このソースプログラムを UTF-8 で保存し Windows で実行すると, コマンドプロンプト画面に文字が正しく表示されるはずだ。
char str[256];
utf82sjis("文字列定数を UTF-8 で書くと「ソ構十申貼能表」などが文字化けしません", str); /* UTF-8 to SJIS */
fprintf(stderr,"%s\n", str); /* 端末画面に出力 */
じつは, 文字コードを変換する関数として iconv() という汎用の関数があり, Mac OS X
ではライブラリが標準でインストールされている。Windows でも, ライブラリをインストールすれば C
で使えるようになる。
しかし, プログラムを実行するときにライブラリが必要なので, どの環境でもプログラムが動くというわけにはいかない。
一般に Unicode を他の文字コードに変換するためには, 文字コードごとに変換テーブルが必要なので,
多くの文字コードに対応した変換プログラムはどうしても大げさになってしまうのだ。
ただ, 変換先の文字コードが1つだけのときは変換テーブルも1つで済むので, 自前で持たせたというわけだ。
[ダウンロード]
usjconv.h (147 KB) … 文字コード変換関数 utf82sjis() と変換テーブルを含むヘッダファイル (2021/11版)
ここで紹介したプログラムでは, JIS X
0208-1990 + NEC 拡張文字 (正しくは NEC 特殊文字と NEC 選定拡張文字)
という日本語文字セットを使っており JIS コード順でビットマップデータを収容している。字形は JIS X 0213-2004
に準拠している。ところで, Windows で使われている日本語文字セット (CP932) は, さらに IBM
拡張文字も含んでいる。
しかし, NEC 拡張文字と IBM 拡張文字は, 同じ文字 (UTF-8 コードが同一) が別々の JIS
コード領域に定義されたものだ。
同じ文字のデータを2重に持つのは無駄なので, ここではコード番号の若い NEC
拡張文字でまにあわせている。
したがって, 拡張文字の UTF-8 からのコード変換では, Windows 標準の文字コード変換規則
(Wikipedia の「コードページ932」参照) とは異なり, NEC 拡張文字のコードに変換されている。
なお, 本プログラムは Apple システム外字には対応していない。